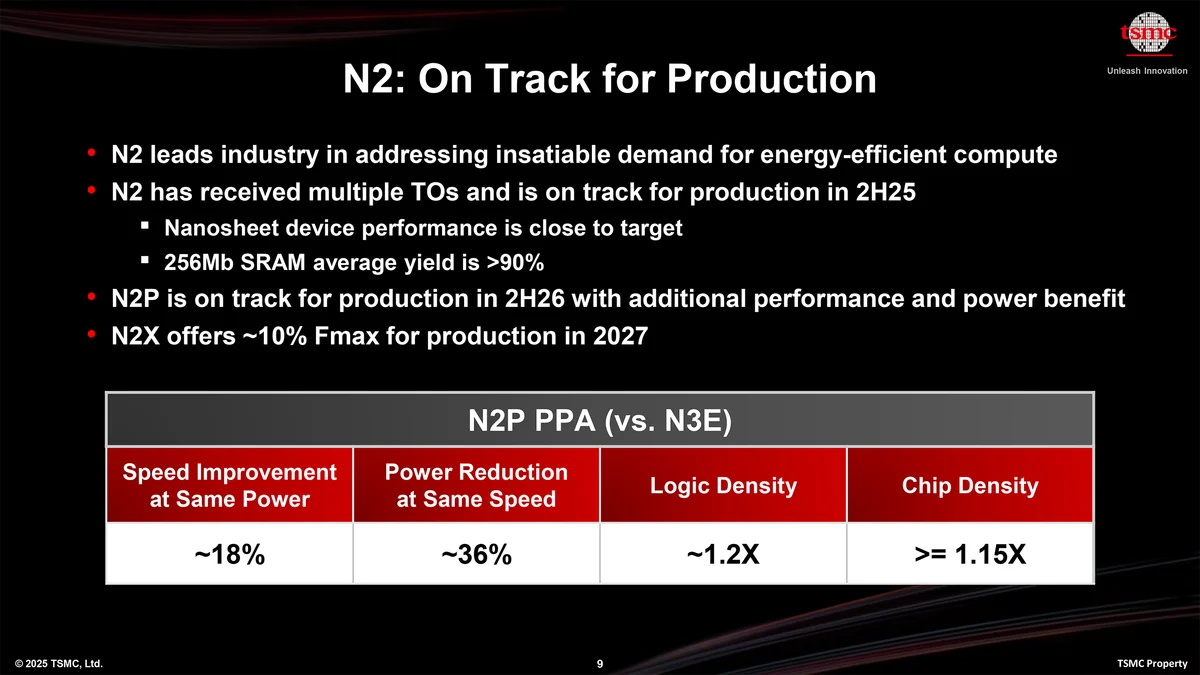
NVIDIA, 24 Aralık 2025’te imzalanan yaklaşık 20 milyar dolarlık lisans anlaşmasının ardından Groq’un LPU teknolojisini 2028’de çıkacak Feynman GPU’larına taşıyor. TSMC’nin hibrit bağlama yöntemiyle LPU zarları GPU’nun üzerine dikey istiflenecek; ana işlem zarı ise 1.6nm A16 teknolojisiyle üretilecek. Hedef net: yapay zekâ çıkarımında daha düşük gecikme ve daha yüksek verimlilik.
LPU’lar dikey istifleniyor: hız, verim, ölçek
Groq’un Language Processing Unit yaklaşımı, büyük dil modellerinde kritik darboğaz olan bellek ve veri hareketini kısaltıyor. TSMC hibrit bağlama sayesinde, ayrı SRAM bankaları taşıyan LPU zarları GPU’ya AMD’nin 3D V-Cache çözümünü anımsatan biçimde yaklaştırılıyor. Böylece parametrelere erişim süresi kısalıyor; watt başına performans artıyor.
Kısacası: veriye yakın hesap, gecikmeyi budar.
- Çıkarımda tek haneli milisaniye seviyelerine inen gecikmeler
- Enerji verimliliğinde belirgin kazanımlar
- Modüler üretimle maliyet ve verimde denge
Anlaşmanın perde arkası ve pazar etkisi
Anlaşma, Groq’un kurucusu Jonathan Ross ile başkan Sunny Madra’nın NVIDIA’ya katılmasını da kapsıyor. Bu transfer, Feynman mimarisine LPU uzmanlığının doğrudan enjekte edilmesi anlamına geliyor. 2028 yol haritası, yapay zekâ çıkarımında “rakipsiz konum” hedefini işaret ederken rekabeti de kızıştıracak.
Elbette zorluklar var: istifli paketlemede ısı yönetimi, yazılım tarafında CUDA ekosistemine LPU hızlandırıcılarının yerel entegrasyonu ve tedarik planlaması. Ancak modüler zar tasarımı verimi yükseltip maliyeti dengeleyebilir; bu sayede geliştirme döngüleri kısalabilir.
Önümüzdeki iki yılda prototiplerin görünmesi bekleniyor. İlk performans verileri, üretim olgunluğu ve geliştirici araçları bu hikâyeyi belirleyecek. Planlandığı gibi giderse, 2028 Feynman serisi yapay zekânın ritmini bir kez daha yukarı çekebilir; sakin ama güçlü bir adım.
İlgili Haberler

Yorumlar(0)